Getting Started with Oracle Cloud Infrastructure Data Flow
This tutorial introduces you to Oracle Cloud Infrastructure Data Flow, a service that lets you run any Apache Spark Application at any scale with no infrastructure to deploy or manage.
If you've used Spark before, you'll get more out of this tutorial, but no prior Spark knowledge is required. All Spark applications and data have been provided for you. This tutorial shows how Data Flow makes running Spark applications easy, repeatable, secure, and simple to share across the enterprise.
- How to use Java to perform ETL in a Data Flow Application .
- How to use SparkSQL in a SQL Application.
- How to create and run a Python Application to perform a simple machine learning task.
You can also perform this tutorial using spark-submit from CLI or using spark-submit and Java SDK.
- It's serverless, which means you don't need experts to provision, patch, upgrade or maintain Spark clusters. That means you focus on your Spark code and nothing else.
- It has simple operations and tuning. Access to the Spark UI is a click away and is governed by IAM authorization policies. If a user complains that a job is running too slow, then anyone with access to the Run can open the Spark UI and get to the root cause. Accessing the Spark History Server is as simple for jobs that are already done.
- It is great for batch processing. Application output is automatically captured and made available by REST APIs. Do you need to run a four-hour Spark SQL job and load the results in your pipeline management system? In Data Flow, it's just two REST API calls away.
- It has consolidated control. Data Flow gives you a consolidated view of all Spark applications, who is running them and how much they consume. Do you want to know which applications are writing the most data and who is running them? Simply sort by the Data Written column. Is a job running for too long? Anyone with the right IAM permissions can see the job and stop it.
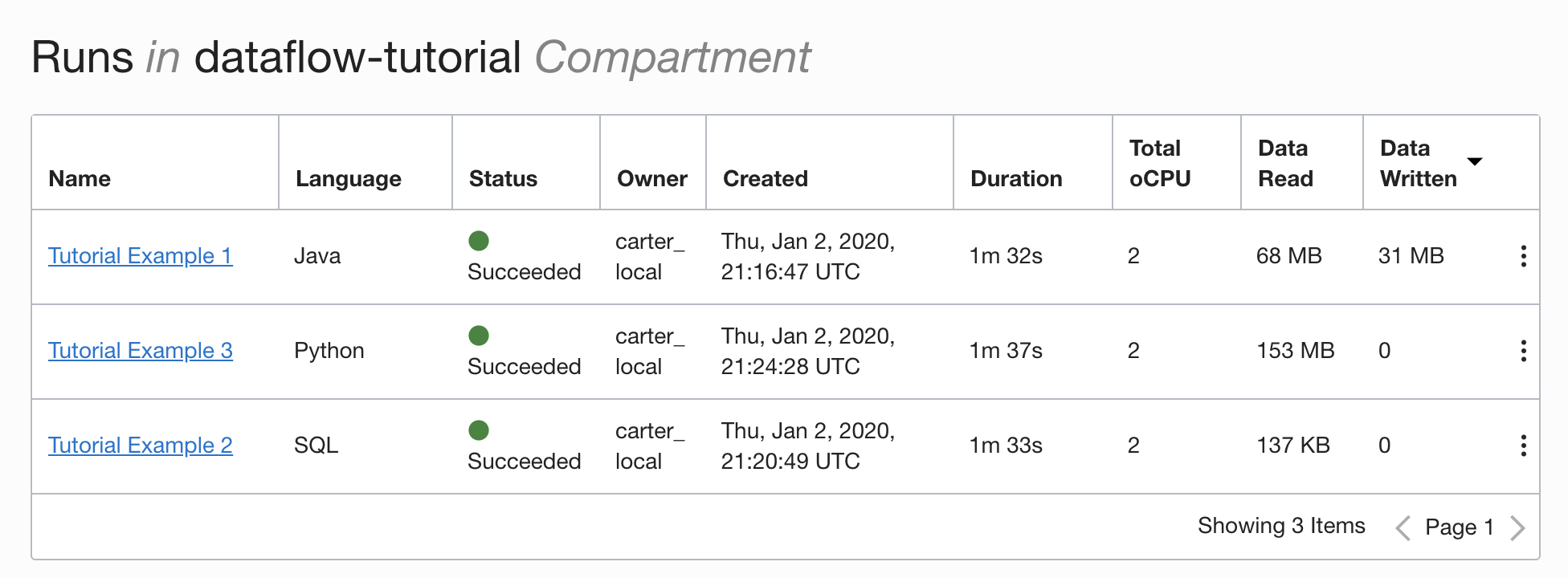
Before You Begin
To successfully perform this tutorial, you must have Set Up Your Tenancy and be able to Access Data Flow.
Before Data Flow can run, you must grant permissions that allow effective log capture and run management. See the Set Up Administration section of Data Flow Service Guide, and follow the instructions given there.
- From the Console, click the navigation menu to display the list of available services.
- Click Analytics & AI.
- From under Big Data, click Data Flow.
- Click Applications.
1. ETL with Java
An exercise to learn how to create a Java application in Data Flow
The steps here are for using the Console UI. You can complete this exercise using spark-submit from CLI or spark-submit with Java SDK.
The most common first step in data processing applications, is to take data from some source and get it into a format that's suitable for reporting and other forms of analytics. In a database, you would load a flat file into the database and create indexes. In Spark, your first step is to clean and convert data from a text format into Parquet format. Parquet is an optimized binary format supporting efficient reads, making it ideal for reporting and analytics. In this exercise, you take source data, convert it into Parquet, and then do a few interesting things with it. The dataset is the Berlin Airbnb Data dataset, downloaded from the Kaggle website under the terms of the Creative Commons CC0 1.0 Universal (CC0 1.0) "Public Domain Dedication" license.

The data is provided in CSV format and the first step is to convert this data to Parquet
and store it in object store for downstream processing. A Spark application,
called oow-lab-2019-java-etl-1.0-SNAPSHOT.jar, is provided
to make this conversion. The objective is to create a Data Flow Application which runs this
Spark app, and run it with the correct parameters. Because you're starting
out, this exercise guides you step by step, and provides the parameters you
need. Later you need to provide the parameters yourself, so you must
understand what you're entering and why.
Create a Data Flow Java Application from the Console, or with Spark-submit from the command line or using SDK.
Create a Java application in Data Flow from the Console.
Create a Data Flow Application.
- Navigate to the Data Flow service in the Console by expanding the hamburger menu on the top left and scrolling to the bottom.
- Highlight Data Flow, then select Applications. Choose a
compartment where you want the Data Flow
applications to be created. Finally, click Create Application.

- Select Java Application and enter a name for the Application, for example,
Tutorial Example 1.
- Scroll down to Resource Configuration. Leave all these values as their defaults.

- Scroll down to Application Configuration. Configure the application as follows:
- File URL: is the location of the JAR file in object storage. The
location for this application is:
oci://oow_2019_dataflow_lab@idehhejtnbtc/oow_2019_dataflow_lab/usercontent/oow-lab-2019-java-etl-1.0-SNAPSHOT.jar - Main Class Name: Java applications need a Main Class Name which
depends on the application. For this exercise, enter
convert.Convert - Arguments: The Spark application expects two command line parameters,
one for the input and one for the output. In the Arguments field,
enter You're prompted for default values, and it's a good idea to enter them now.
${input} ${output}

- File URL: is the location of the JAR file in object storage. The
location for this application is:
- The input and output arguments are:
- Input:
oci://oow_2019_dataflow_lab@idehhejtnbtc/oow_2019_dataflow_lab/usercontent/kaggle_berlin_airbnb_listings_summary.csv - Output:
oci://<yourbucket>@<namespace>/optimized_listings
Double-check the Application configuration, to confirm it looks similar to the following:
 Note
Note
You must customize the output path to point to a bucket in the tenant. - Input:
- When done, click Create. When the Application is created, you see it in the Application
list.

Congratulations! You've created your first Data Flow Application. Now you can run it.
Use spark-submit and CLI to create a Java Application.
Complete the exercise to create a Java application in Data Flow using spark-submit and Java SDK.
These are the files to run this exercise, and they're available on the following public Object Storage URIs:
- Input files in CSV
format:
oci://oow_2019_dataflow_lab@idehhejtnbtc/oow_2019_dataflow_lab/usercontent/kaggle_berlin_airbnb_listings_summary.csv - JAR
file:
oci://oow_2019_dataflow_lab@idehhejtnbtc/oow_2019_dataflow_lab/usercontent/oow-lab-2019-java-etl-1.0-SNAPSHOT.jar
Having created a Java application you can run it.
- If you followed the steps precisely, all you need to do is highlight your Application in the list, click Actions menu, and click Run.
- You're presented with the ability to customize parameters before running the Application. In your case, you entered the precise values ahead-of-time, and you can start running by clicking Run.
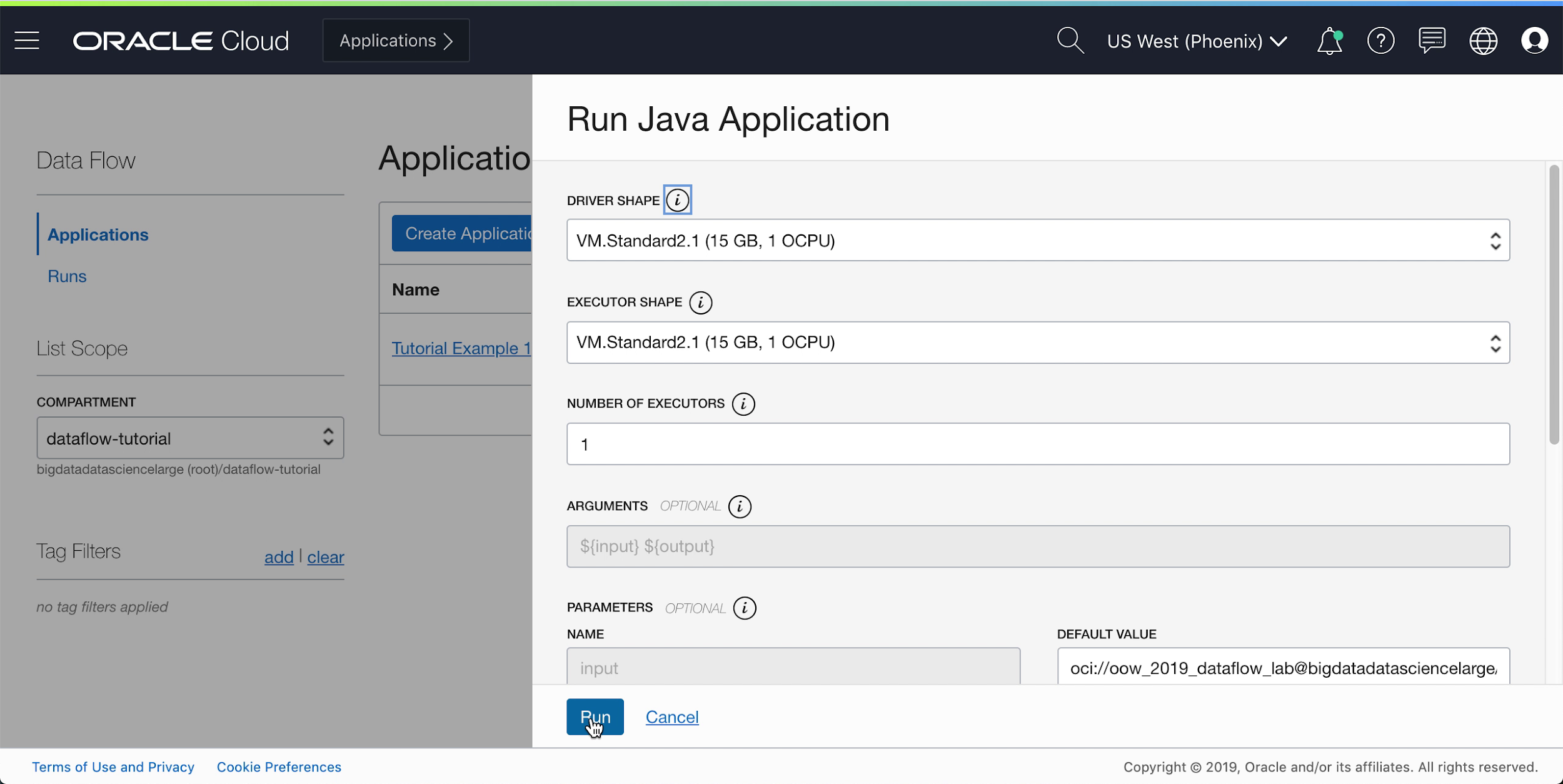
While the Application is running, you can optionally load the Spark UI to monitor progress. From the Actions menu for the run in question, select Spark UI.
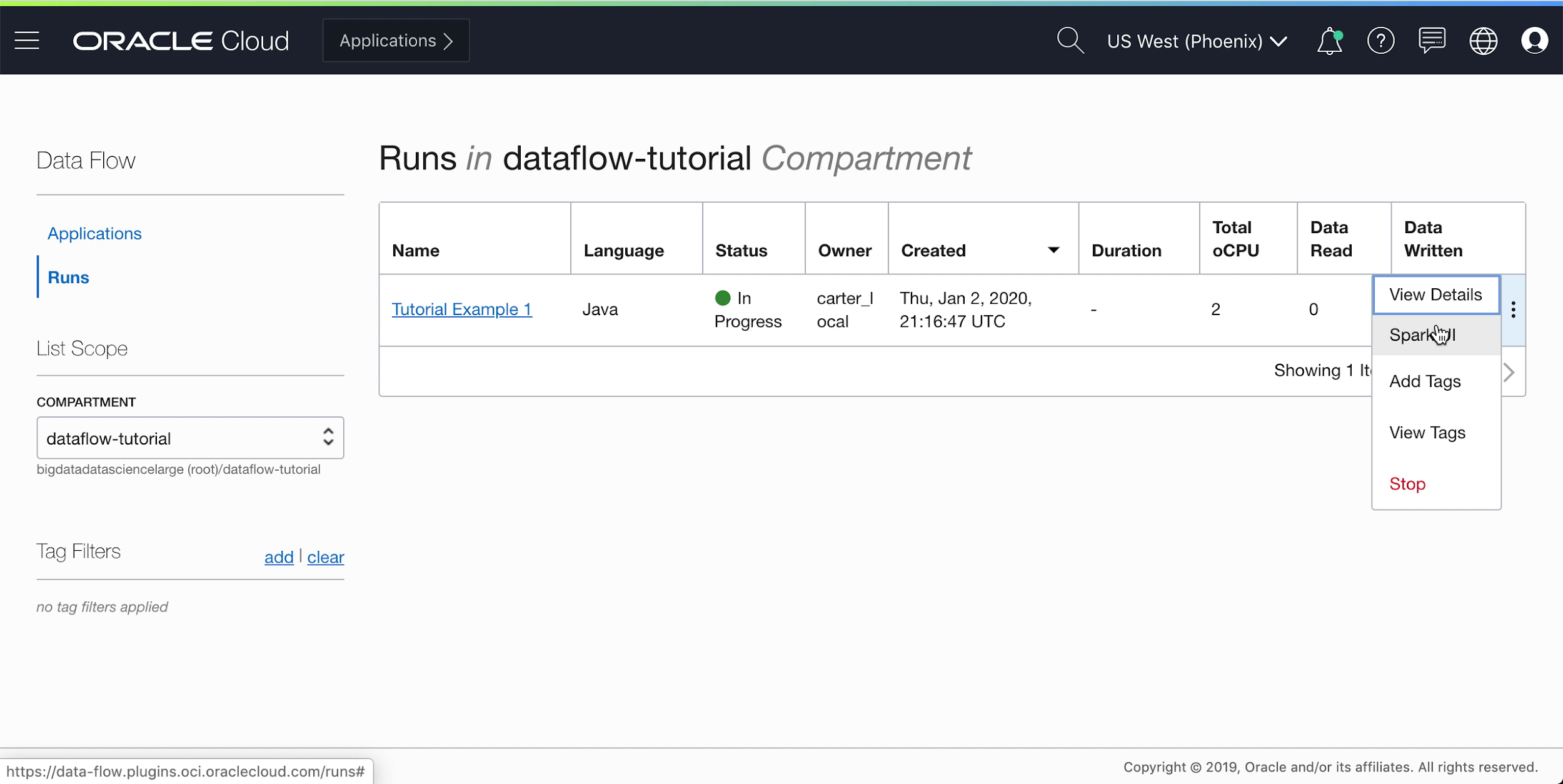
- You're automatically redirected to the Apache Spark UI, which is useful for debugging and
performance tuning.
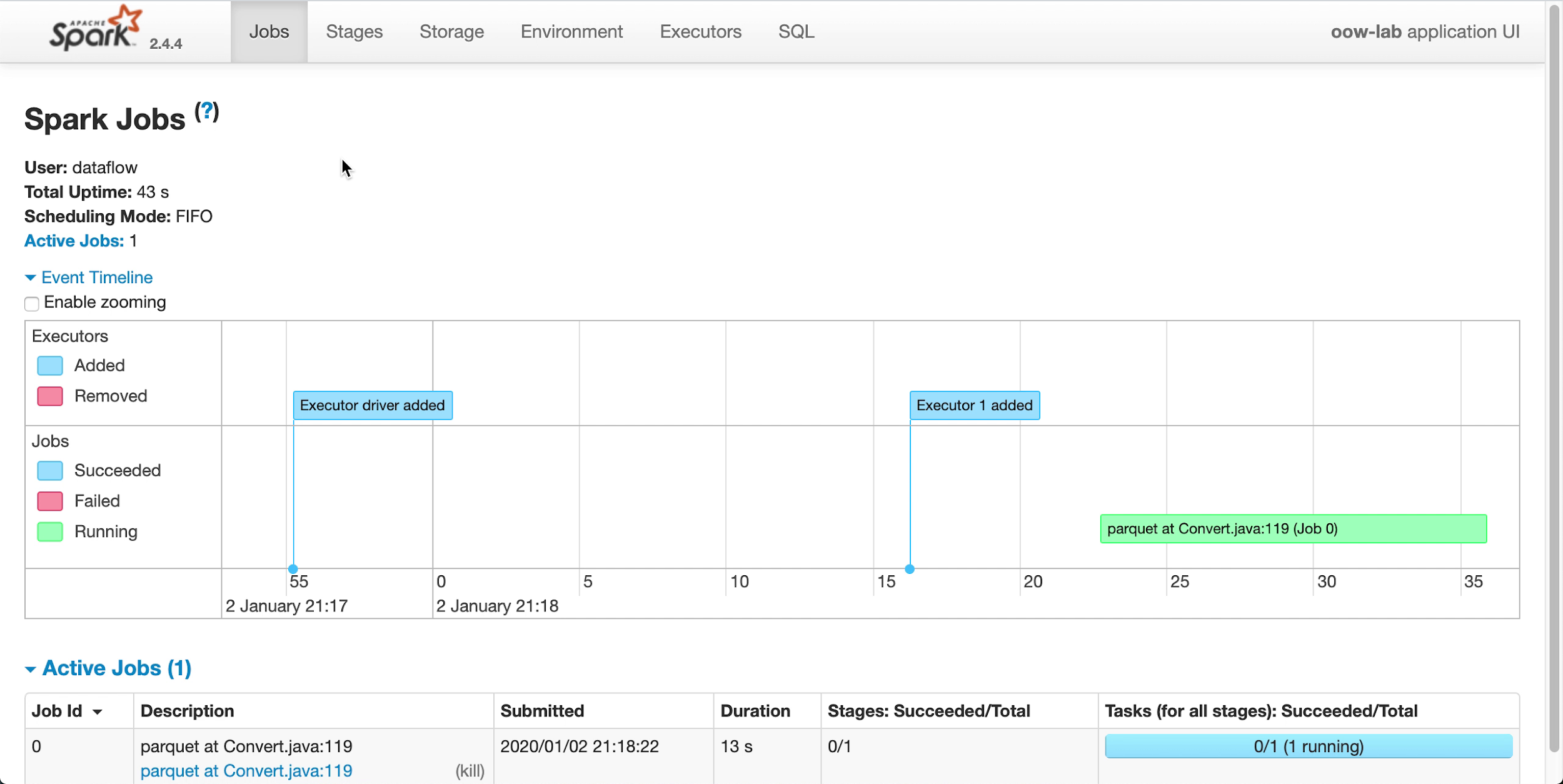
After a minute or so your Run should show successful completion with a State of
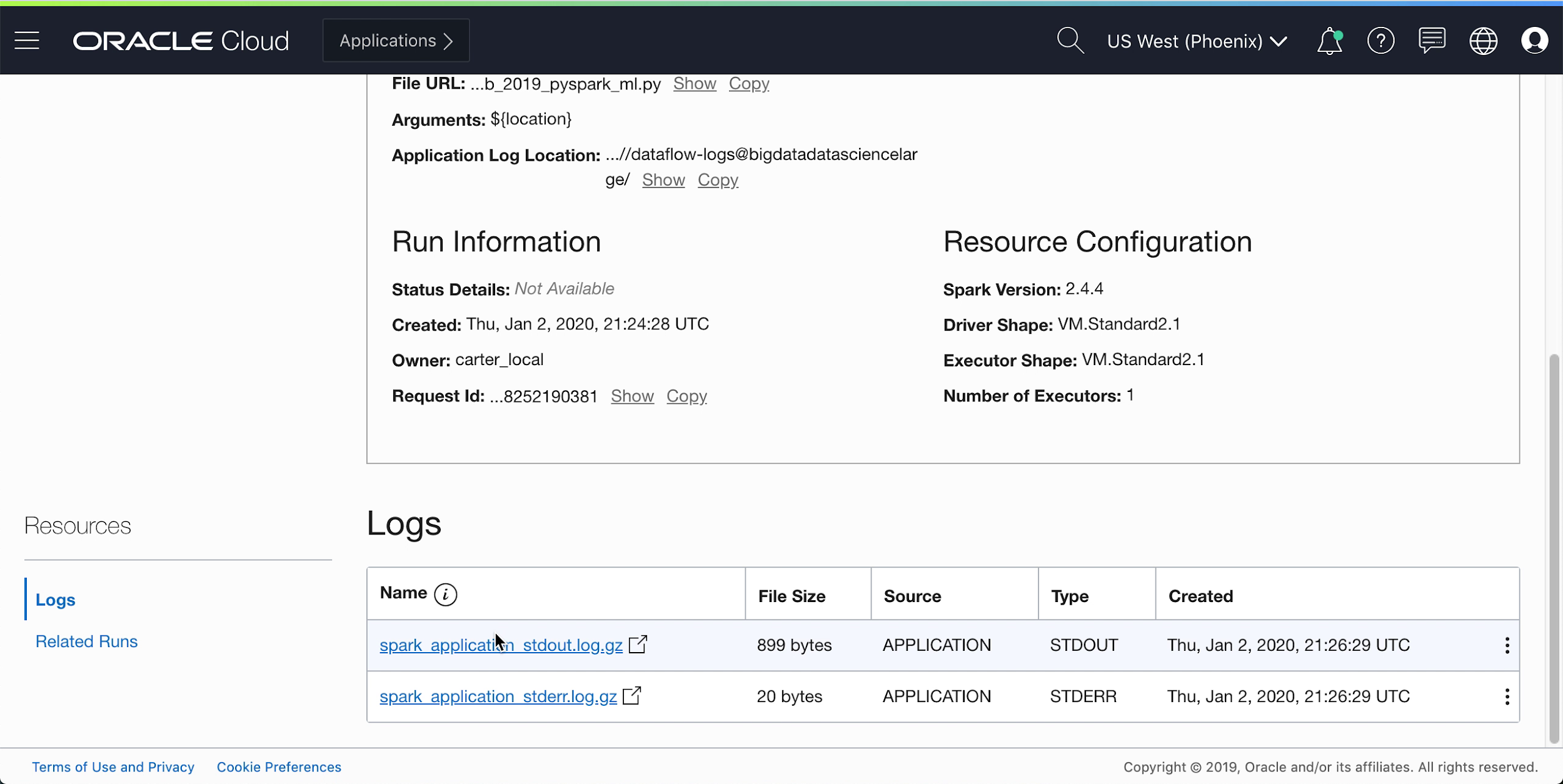
Succeeded: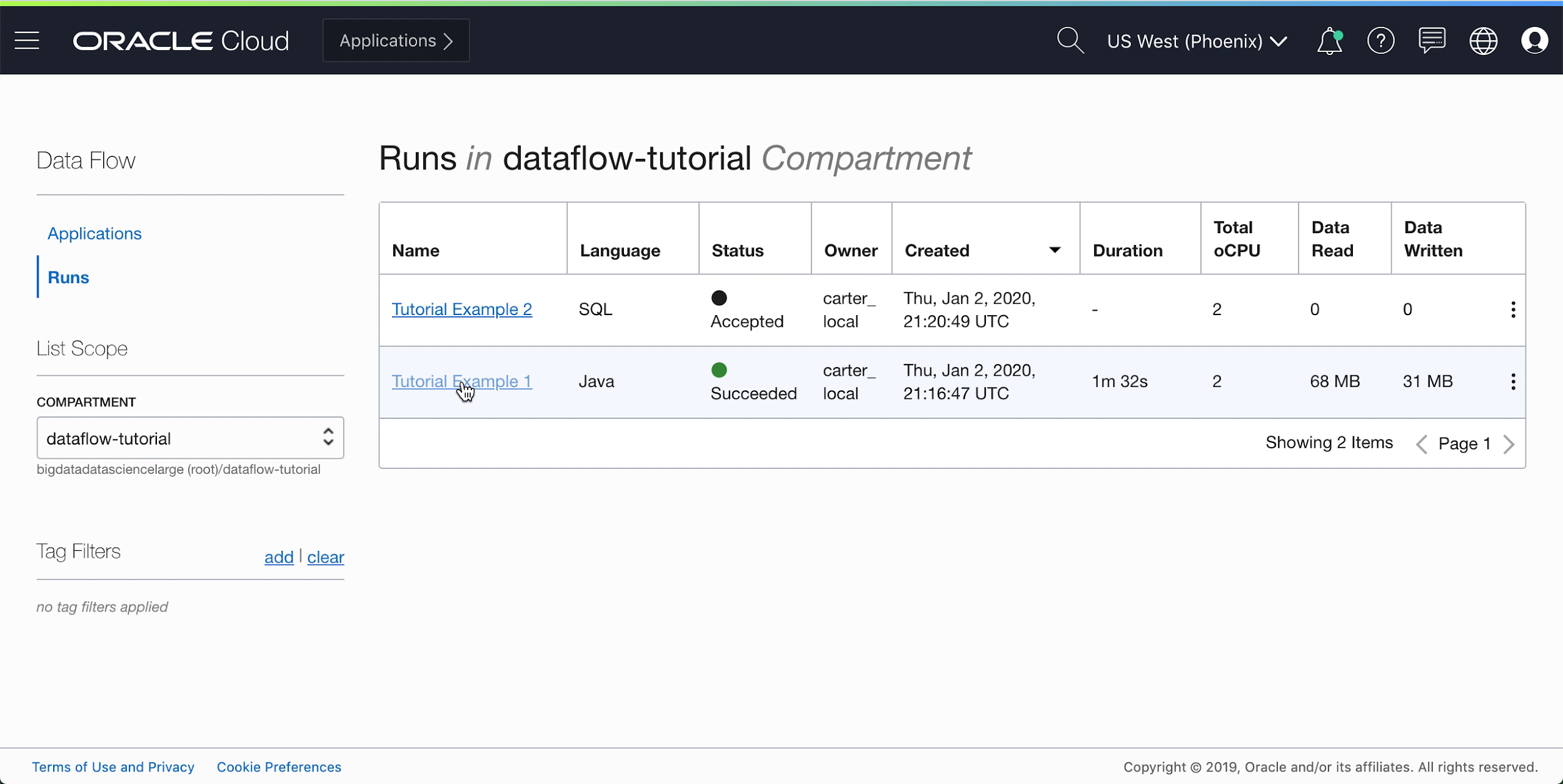
Drill into the Run to see more details, and scroll to the bottom to see a listing of logs.
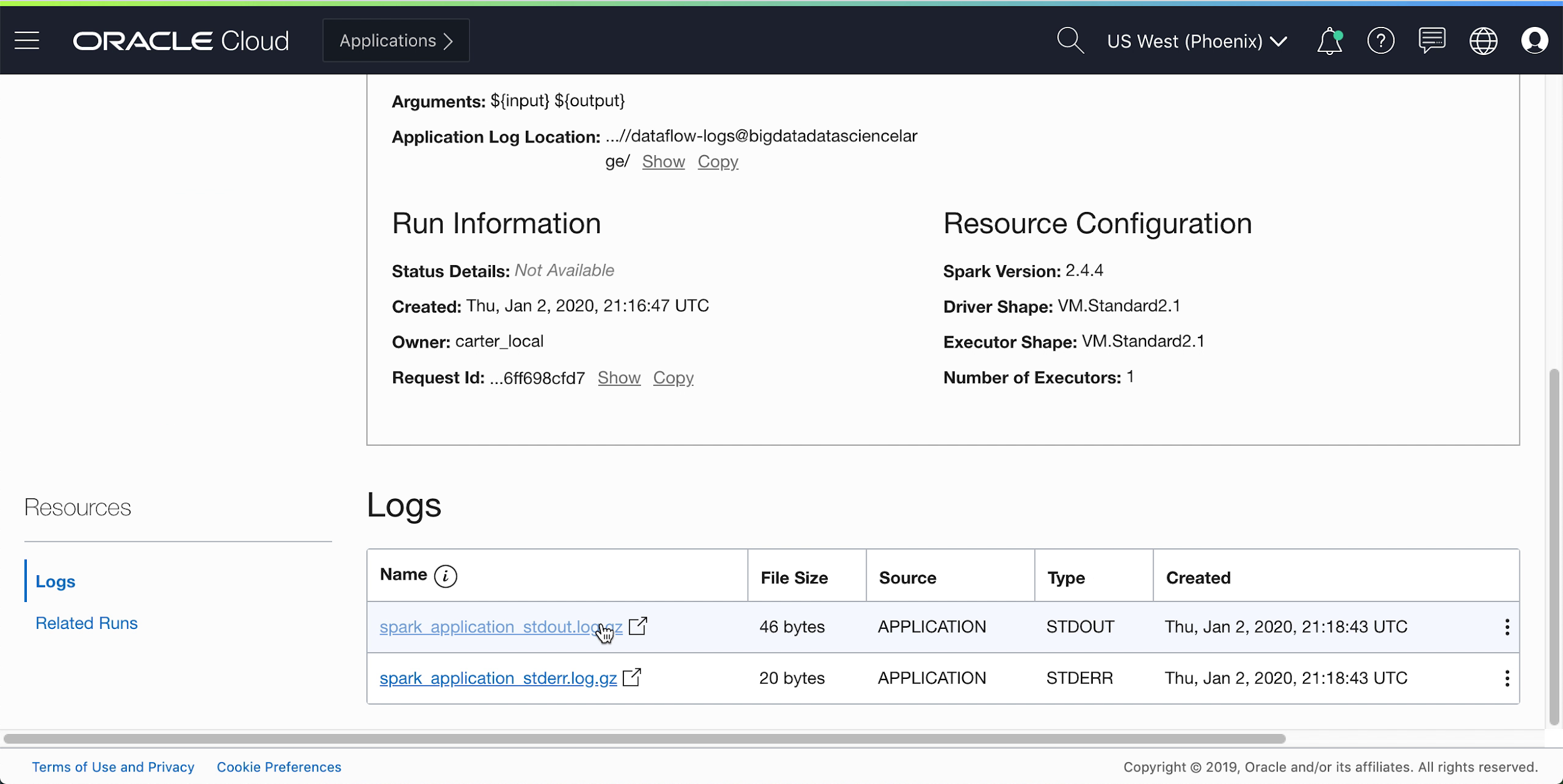
When you click the spark_application_stdout.log.gz file, you should see the following log output:

- You can also navigate to your output object storage bucket to confirm that new files have been
created.
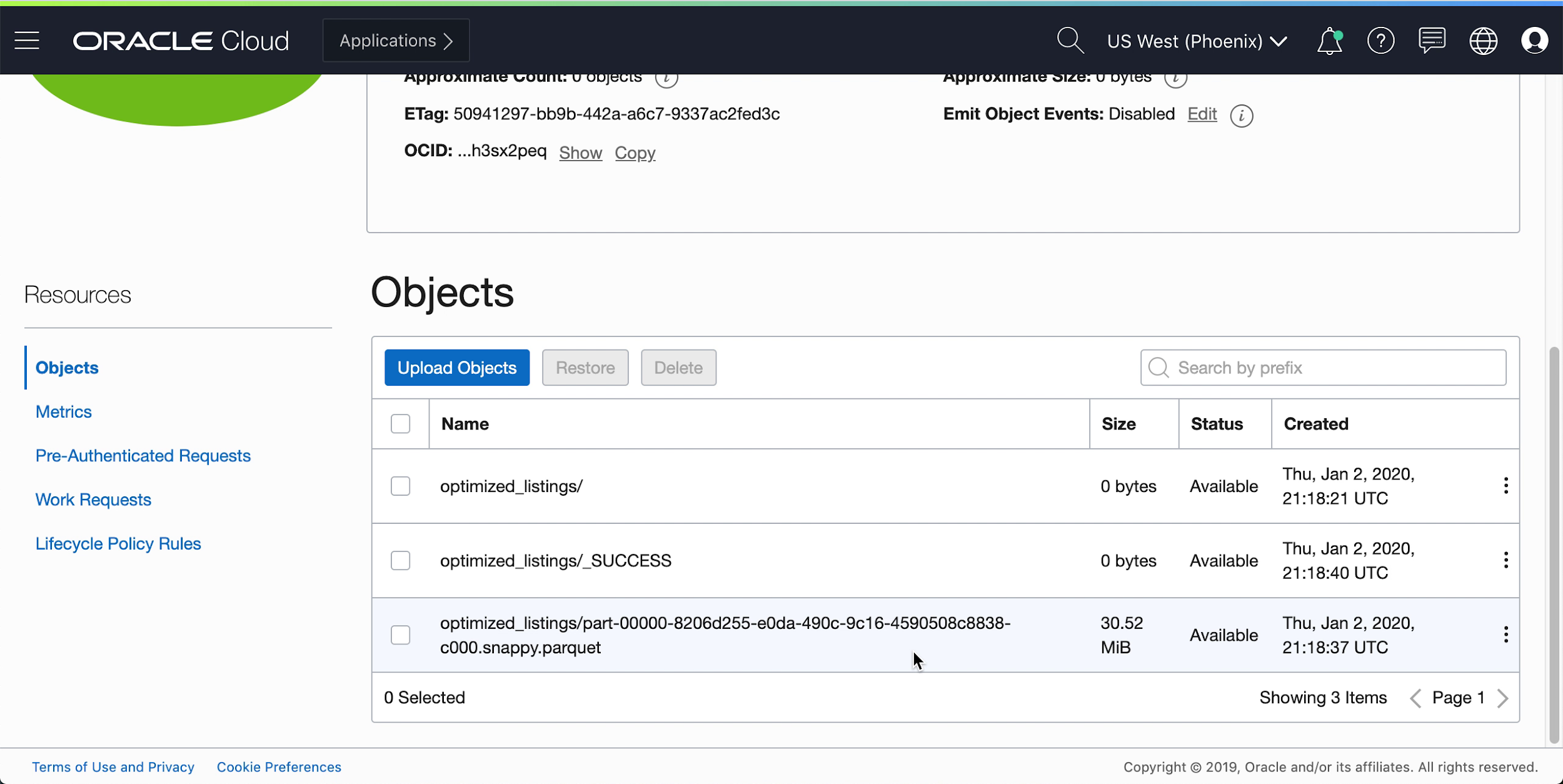
These new files are used by later applications. Ensure you can see them in your bucket before moving onto the next exercises.
2. SparkSQL Made Simple
In this exercise, you run a SQL script to perform basic profiling of a dataset.
This exercise uses the output you generated in 1. ETL with Java. You must have completed it successfully before you can try this one.
The steps here are for using the Console UI. You can complete this exercise using spark-submit from CLI or spark-submit with Java SDK.
As with other Data Flow Applications, SQL files are stored in object storage and might be shared among many SQL users. To help this, Data Flow lets you parameterize SQL scripts and customize them at runtime. As with other applications you can supply default values for parameters which often serve as valuable clues to people running these scripts.
The SQL script is available for use directly in the Data Flow Application, you don't need to create a copy of it. The script is reproduced here to illustrate a few points.
Reference text of the SparkSQL Script: 
- The script begins by creating the SQL tables we need. Currently, Data Flow doesn't have a persistent SQL catalog so all scripts must begin by defining the tables they require.
- The table's location is set as
${location}This is a parameter which the user needs to supply at runtime. This gives Data Flow the flexibility to use one script to process many different locations and to share code among different users. For this lab, we must customize${location}to point to the output location we used in Exercise 1 - As we will see, the SQL script's output is captured and made available to us under the Run.
- In Data Flow, create a SQL Application, select SQL as type, and
accept default resources.

- Under Application Configuration, configure the SQL Application as follows:
- File URL: is the location of the SQL file in object storage. The
location for this application is:
oci://oow_2019_dataflow_lab@idehhejtnbtc/oow_2019_dataflow_lab/usercontent/oow_lab_2019_sparksql_report.sql - Arguments: The SQL script expects one parameter, the location of
output from the prior step. Click Add Parameter and enter a parameter
named
locationwith the value you used as the output path in step a, based on the templateoci://[bucket]@[namespace]/optimized_listings
When you're done, confirm that the Application configuration looks similar to the following:

- File URL: is the location of the SQL file in object storage. The
location for this application is:
- Customize the location value to a valid path in your tenancy.
- Save the Application and run it from the Applications list.
- After the Run is complete, open the Run:
- Navigate to the Run logs:
- Open spark_application_stdout.log.gz and confirm that the output agrees with the
following output. Note
Your rows might be in a different order from the picture but values should agree.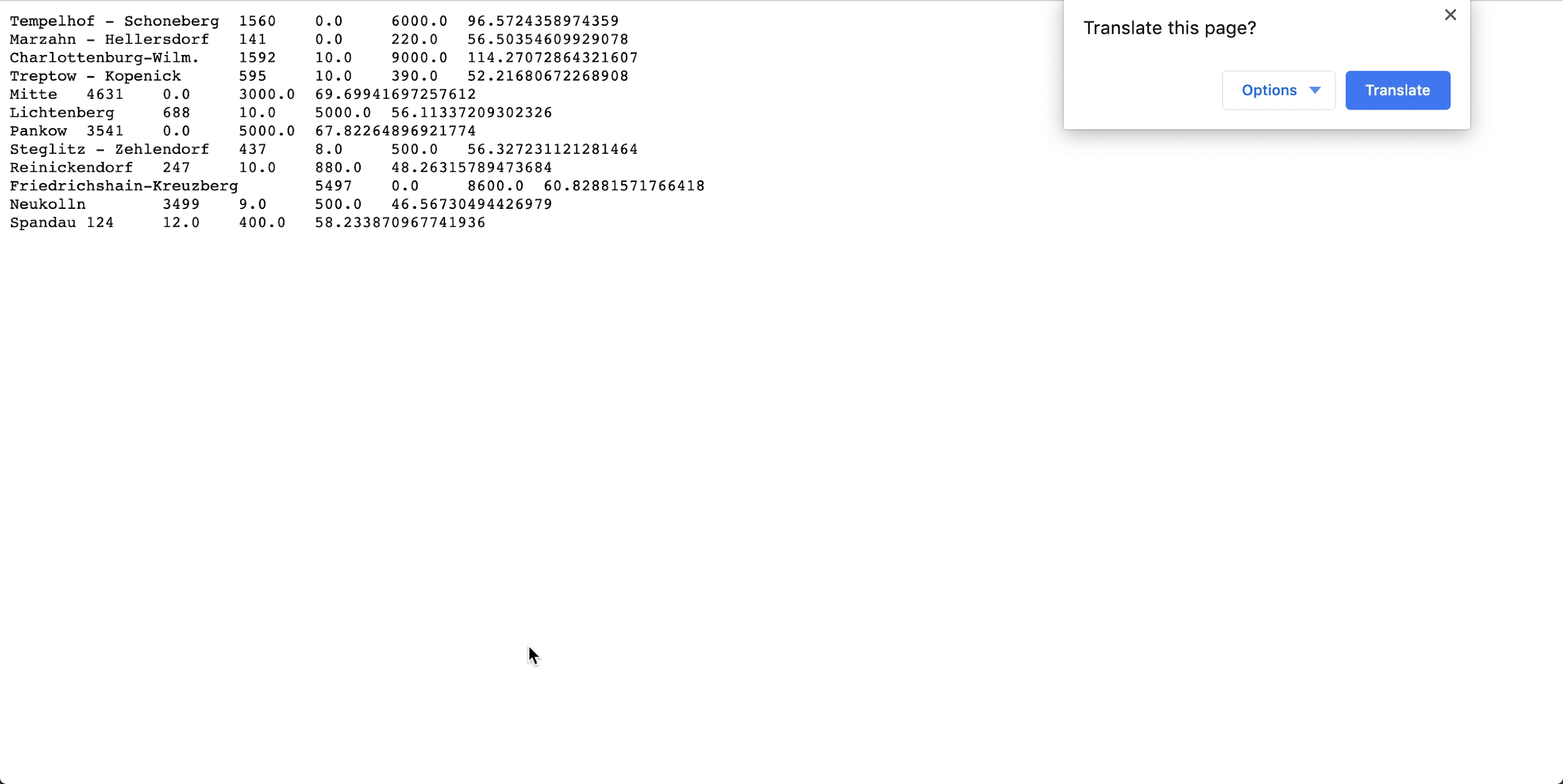
- Based on your SQL profiling, you can conclude that, in this dataset, Neukolln has the lowest average listing price at $46.57, while Charlottenburg-Wilmersdorf has the highest average at $114.27 (Note: the source dataset has prices in USD rather than EUR.)
This exercise has shown some key aspects of Data Flow. When a SQL application is in place anyone can easily run it without worrying about cluster capacity, data access and retention, credential management, or other security considerations. For example, a business analyst can easily use Spark-based reporting with Data Flow.
3. Machine Learning with PySpark
Use PySpark to perform a simple machine learning task over input data.
This exercise uses the output from 1. ETL with Java as its input data. You must have successfully completed the first exercise before you can try this one. This time, your objective is to identify the best bargains among the various Airbnb listings using Spark machine learning algorithms.
The steps here are for using the Console UI. You can complete this exercise using spark-submit from CLI or spark-submit with Java SDK.
A PySpark application is available for you to use directly in your Data Flow Applications. You don't need to create a copy.
Reference text of the PySpark script is provided here to illustrate a few points: 
- The Python script expects a command line argument (highlighted in red). When you create the Data Flow Application, you need to create a parameter with which the user sets to the input path.
- The script uses linear regression to predict a price per listing, and finds the best bargains by subtracting the list price from the prediction. The most negative value indicates the best value, per the model.
- The model in this script is simplified, and only considers square footage. In a real setting you would use more variables, such as the neighborhood and other important predictor variables.
Create a PySpark Application from the Console, or with Spark-submit from the command line or using SDK.
Create a PySpark application in Data Flow using the Console.
-
Create an Application, and select the Python type.

-
Double-check the Application configuration, and confirm it's similar to the
following:

Create a PySpark application in Data Flow using Spark-submit and CLI.
Create a PySpark application in Data Flow using Spark-submit and SDK.
- Run the Application from the Application list.
When the Run completes, open it and navigate to the logs.
- Open the spark_application_stdout.log.gz file. Your output should be identical to the
following:

From this output, you see that listing ID 690578 is the best bargain with a predicted price of $313.70, compared to the list price of $35.00 with listed square footage of 4639 square feet. If it sounds a little too good to be true, the unique ID means you can drill into the data, to better understand if it really is the steal of the century. Again, a business analyst could easily consume the output of this machine learning algorithm to further their analysis.
What's Next
Now you can create and run Java, Python, or SQL applications with Data Flow, and explore the results.
Data Flow handles all details of deployment, tear down, log management, security, and UI access. With Data Flow, you focus on developing Spark applications without worrying about the infrastructure.